VALL-E论文读书笔记#
- 主要是逐句翻译
- 每部分结尾记一些笔记感想
第零部分:摘要#
我们提出了一种用于文本到语音合成 (text to speechTTS) 的语言建模方法。具体来说,我们使用从现成的(off-the-shelf)神经音频编解码器模型中提取的离散编码训练了一个神经编解码器语言模型(称之为 VALL-E),并将 TTS 视为一个条件语言建模任务,而不是像以往工作那样进行连续信号回归(continuous signal regression)。在预训练阶段,我们将 TTS 训练数据扩展到 6 万小时的英语语音,比现有系统的数据量大数百倍。VALL-E 展现出上下文学习能力,仅需 3 秒钟的未见过说话人的录音作为声学提示,即可合成高质量的个性化语音。实验结果表明,VALL-E 在语音自然度和说话人相似度方面显著优于目前最先进的零样本 TTS 系统。此外,我们发现 VALL-E 能够在合成过程中保留说话人的情感和声学提示的声学环境。访问 https://aka.ms/valle 查看我们工作的demo。
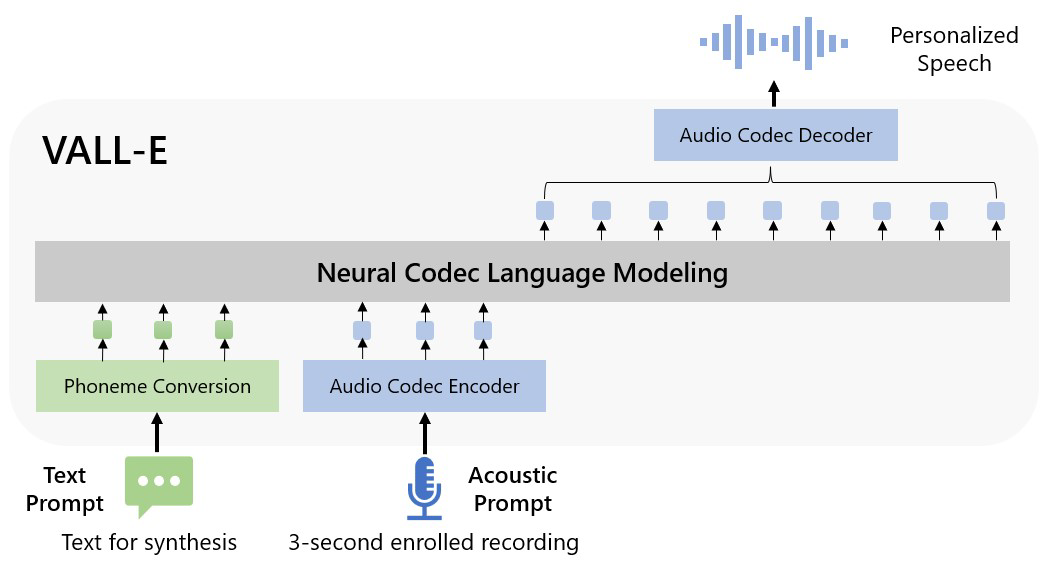
第一部分:引入介绍#
通过神经网络和端到端(end-to-end)模型的发展,过去一个阶段中此领域已有抓马的发展,目前级联TTS(文本转语音)系统通常采用梅尔频谱作为中间特征表示,建立包含声学模型和声码器(vocoder)的工作流水线(pipeline)。尽管先进的TTS系统已经可以生成高质量的单说话人/多说话人说话音频了,但它们依赖于录音室级别的高质量纯净录音数据。而从互联网上获取的大规模庞杂的数据不符合这个要求,使用这些数据还会导致输出性能劣化(performance degradation)。并且因为训练数据的规模相对较小,导致当前的TTS系统泛化能力较差:对于零样本(zero-shot)TTS场景,未见过说话人的音色相似度与自然度退步严重。为了解决零样本TTS的问题,有一些现有解决方案如引入说话人适配器和说话人编码模式,通常需要引入额外的微调、复杂的预设特征或臃肿的结构工程。
受文本合成领域的成功的启迪,不同于通过一个复杂的专用网络来解决这个问题,我们得出的终极解决方案是用尽可能大规模的丰富数据来训练模型。近几年来我们见到了文本语言模型随着数据量提升而取得的巨大性能提升:从16GB的原始文本语料到160GB、570GB,最终达到了1TB左右。把他们的成功经验引入语音合成领域,我们得到了VALL-E,第一个基于大规模的多样化的多说话人数据集训练的TTS语言模型。为了实现个性化合成(比如零样本TTS),VALL-E由三秒钟左右的录音提示(Acoustic Prompt)与文本提示来生成声学标记(Acoustic Tokens),用于准确的约束(constrain)说话人特征与文本内容信息。最终,生成的声学标记通过神经网络编码器(codec)的解码器被用于构建最终的输出波形。这种基于离散声学标记(discrete acoustic tokens)的方法使我们能把TTS工作视作条件编码语言模型,因此先进的基于提示词的大模型技术可以被迁移到TTS工作上。声学标记还使我们在推理时,能够通过使用不同的采样策略来生成丰富的个性化的TTS结果。
我们使用LibriLight数据集来训练VALL-E,这是一个包含6万小时&7000+说话人的英语音频数据集。原数据集只有音频内容,所以我们部署了一个语音识别模型用于生成语音对应的文本。与此前的TTS模型用到的训练集(如LibriTTS)相比,我们用的的数据包括更多的嘈杂环境下的说话内容与不准确的转述,但同时也包含更丰富的说话人与韵律(prosodies)我们自信我们提出的这个方法对噪音有着更强的鲁棒性(robust)并且在更大规模的数据训练下有着更好的泛化性能。值得注意的是现有的TTS系统总是只用数十小时的单说话人数据或数百小时的多说话人数据训练——训练数据量不及VALL-E的百分之一。下方的表一汇总了VALL-E的创新:语言模型思想在TTS领域的实践,使用语音编码器编码获取跨媒介的特征表示,使用了大规模的多样数据,拥有强大的情景学习(in-context learning)能力
| 表一 | ||
|---|---|---|
| NULL | 当前模型 | VALL-E |
| 中间表示方式 | 梅尔频谱 | 音频编码 |
| 目标函数 | 连续信号回归 | 语言模型 |
| 训练数据 | 少于600小时 | 6万小时 |
| 情境学习能力 | ❌ | ✅ |
我们在LibriSpeech和VCTK数据集上评估了VALL-E模型,提前确保了没有任何测试的说话人数据有泄露到训练数据中。无论是说话人相似度还是说话人自然度,VALL-E的输出表现都是零样本TTS系统的SOTA1。在LibriSpeech上获得了+0.12分的众包意见得分2和+0.93的相似度平均意见得分3的提高。它甚至取得了比真实人声还要高0.04的众包意见得分,这说明了合成的未见过说话人的语音就像是VCTK数据集中的真实人类录音一样自然。更进一步的,质量分析数据显示即使是在文本与目标合成对象不变的情况下,VALL-E也能够合成出多样的输出,这对于语音识别(ASR)任务的训练数据合成而言是一个重大利好。我们也注意到VALL-E能够保持住音频提示中的声学环境(如混响)与情感信息(如愤怒)。
总而言之,我们做出了如下贡献:
- 我们推出了VALL-E,第一个拥有着GPT-3级别强大的情境学习能力的TTS框架。我们把传统的梅尔频谱中间表示替换为由声学编码器编码,使TTS工作成为了语言模型任务。它具有情境学习能力并且由此实现了基于提示词策略的零样本TTS工作——不需要额外的结构工程设计/微调作为前置工作即可实现的零样本TTS。
- 我们通过使用大规模的半监督数据,建立了一个在说话人维度上通用的TTS系统,这说明简单的扩展(scaling up)半监督数据在TTS工作中能起到的效果在此前被低估了。
- VALL-E能够在保持声学环境与音频提示中的说话人情绪不变的情况下为相同的输入文本生成多样的音频输出。
- 我们验证了在零样本场景下,VALL-E能合成出高度说话人相似度的自然语音。实验结果显示VALL-E在LibriSpeech和VCTK数据集上的评测结果都是毋庸置疑的SOTA表现
我们欢迎读者们试听我们在demo页面放出的样例。
碎碎念:
- 第一部分总-分结构很明确,依次介绍了现有工作的不足、工作的灵感来源&创新实现思路、独一段介绍了有显著改进数据集情况、和此前TTS工作对比、测试效果,最后总结。内部也有递进关系,从过去到现在,从灵感到实现到效果
- 只是提到了“注意到能保持住音频提示中的声学环境与情感信息”,还是能力涌现而没有给出进一步分析解耦控制这些的尝试
- 通过设计抛弃了预设定声学特征的解决方案,这对于情绪、音色控制有启示意义。比如或许可以把待合成文本的语义深度特征也融入/接续到声学特征表示,从而实现合成语音的情感的表达更为自然符合语境?
第二部分:相关工作#
零样本文本到语音合成(Zero-Shot TTS): 当前的TTS模式可以被分类成级联(cascaded)模式与端到端模式。级联TTS系统通常使用一个声学模型和使用梅尔频谱作为中间表示的声码器相结合的流水线。为了克服声码器的缺陷,端对端TTS模型有意识的同时优化声学模型和声码器。在现实场景中,使用仅有的少量录音数据来个性化定制TTS系统的需求十分旺盛。因此,对零样本多说话人TTS技术的兴趣日益旺盛,并且大部分工作是在级联TTS系统的范畴内完成的。作为先驱者,Arik et al.4提出了说话人适配器与说话人编码方法。在说话人适配器方面,如下工作567尝试用更少的目标说话人数据与针对说话人的参数来提升适配器的效率。有的人8把元学习(meta-learning)技术应用在说话人适配器上,实现了仅需5段样本即可建立合成表现不错的系统。与此同时,基于说话人编码的范式近些年来也取得了巨大进步。说话人基于说话人编码的系统包括一个说话人编码器与一个TTS模块,而说话人编码器可以在说话人验证任务中得到预训练。有实验表明,对于域内说话人(in-domain speaker),这种模型可以做到仅需3秒钟的注册音频即可扩展生成高质量的语音输出。尽管可以使用先进的说话人嵌入模型9来提升未见过说话人合成效果的质量,但据研究10其效果并不尽如人意。还有一种思路是设计先进但复杂的说话人编码器11。基于扩散模型的TTS1213也逐渐涉足零样本TTS领域并取得了优秀的结果。与此前的工作相比,我们大体上依旧是依循级联TTS的思路但是率先使用了音频编码器编码作为中间表示,VALL-E是第一个拥有GPT-3般强上下文学习能力的TTS模型,并且不需要微调、预设特征或复杂的说话人编码器。
口语生成预训练模型(Spoken generative pre-trained models):自监督学习被广泛应用于语音理解领域和语音到语音(speech-to-speech,STS)合成。在STS中,一个热点话题就是如何在无文本设定环境下合成语音。GSLM14提出了基于HuBERT的编码的合成思路,接下来通过把HuBERT编码和VQVAE编码与一个说话人编码器相结合15,进一步提升了表现。AudioLM16使用了相似的思路,但是改用了声音编码器并结合语义编码来合成语音。值得注意的是,不像HifiGAN17等模型需要额外的声码器,AudioLM也能够在不需要额外的声码器的情况下合成语音。AudioLM是STS模型,而VALL-E是TTS模型,后者能够方便地指定控制语音合成的内容。还有一个方向是对神经网络TTS进行预训练。Chung等人的工作18尝试通过自回归预测梅尔频谱来预训练TTS中的说话人解码器。Junyi Ao等人提出了一个统一模态的(Unified-modal)编码器-解码器框架SpeechT519,能够扩大无标签语音与文本用于预训练TTS模型的所有部件。有工作通过使用VQVAE模型,把无标签语音量化成离散标记(discrete tokens)20并使用这些标记到语音的序列(token-to-speech sequence)训练了一个模型。他们指出预训练模型只需要少量真实数据用于微调即可即可。Bai等人21提出了对梅尔频谱的遮罩与重建策略,并且实现了更好的语音编辑与合成表现。先前的TTS预训练工作都只使用了少于一千小时的数据,然而VALL-E使用六万小时的数据进行预训练。除此之外,VALL-E率先使用了语音编码器编码作为中间表示,并且强化了零样本TTS的上下文学习能力。

碎碎念:
- 这部分是进一步的相关现有工作介绍,综述了零样本TTS和口语生成预训练模型的现有工作情况
- 感觉内容重复度有点高,能对这方面的内容有个大致的了解,但是对自身工作的还是那几句车轱辘话来回用
第三部分: 语音量化#
音频的原始存储方式是16位整数序列,生成式模型要直接合成原始音频的话,每个时间步都有2^16^=65536种输出可能性。除此之外,以万为单位的极高音频采样率导致即使只是短短几秒语音,所需的序列的时间步也非常多,这导致原始音频合成更具挑战性了。在这种情形下,我们必须引入音频量化来压缩数值范围和序列长度。μ-律变换可以把每一时间步(的65536个值)压缩为256个离散值,同时还能重建出高质量的原始音频。这种变换方法已经被广泛应用于说话人语音生成模型如WaveNet中。但是由于μ-律变换并没有压缩序列长度,其推理速度依旧非常缓慢。近期,出于特征提取的目的,向量量化被广泛应用于自监督学习领域,典例包括vq-wav2vec和HuBERT。接下来的工作证实了自监督模型输出的编码也能用于重建音频内容且推理速度快于用μ-律变换的WaveNet。然而这个路线的生成效果并不理想:说话人身份特征未被保留,重建质量很低。值得注意的是,AudioLM通过同时使用了自监督模型生成的K-means聚类标记和神经编解码模型生成的声学标记训练模型,实现了高质量的STS生成效果。
在本篇论文中,我们模仿AudioLM的思路,采用神经编解码模型来把语音表征为离散标记。为了压缩音频用于网络传输(?),编解码模型能够将音频波形编码为离散声学标记,并在即使说话人未见过的情况下重建高质量的音频波形。与传统的声学编解码模型实现相比,“基于神经网络的编解码器在低音频码率的情况下表现显著更优异,并且我们相信量化后的标记包含有足够的说话人信息与音频录制环境的信息。与其他量化方式相比,这种音频编解码器有如下优势:
- 包括丰富的说话人信息与声学信息,与HuBERT编码不同,这种编码在重建过程中能保有说话人身份;
- 有现成的能把离散词元转化为波形的解码器可用,无需像以往基于VQ(Vector Quantization,前文的向量量化)方法那样还要额外费心去训练声码器;
VQ-based methods的方法是先提取频谱特征再量化,因此反过来生成还需要声码器
- 通过下采样显著压缩了时间步序列的长度,解决了μ-律变换的效率问题。
我们采用预训练的声学神经编解码器模型EnCodec作为分词器(tokenizer)。EnCodec是一个卷积编解码模型,输入输出都是24kHz的可变码率音频,我们把24kHz的输入音频转化为75Hz的嵌入表示,达成了320倍压缩。每个嵌入表示都由一个残差向量量化(RVQ,Residual Vector Quantization)进行建模。如上方图2所示,我们使用8层级的量化层,每层量化层包括1024个条目(entry) 。这个配置对应于6K码率的24kHz音频重建。
每个量化层2^10^个条目,即对应10个bits;
一共8个层级,每一步的音频特征就是$8\times10=80$bits;
转化为75Hz的嵌入表示,就是 $80 \text{ bits/step} \times 75 \text{ steps/second} = 6000 \text{ bps} = \mathbf{6 \text{ kbps}}$
在这种设置下,假设给定一段10s的音频波形,获得的离散表示是一个$750\times8$ 的矩阵,750对应10s$\times$75Hz的下采样获得的时间步,8对应量化层的数目,矩阵内每个元素是0~1023的整数。采用其他的码率的设置亦可。更高的采样码率需要更多的量化层,相应的也有更好的重建质量。比如如果使用12K码率的EnCodecc配置,我们就要16个量化层。基于从所有的量化层获得的离散编码,EnCodec的卷积解码器能生成实值嵌入(real-valued embeddings)并以24kHz的频率重建波形
- 这部分介绍了模型的前置工作的缘由、横向比对情况、选取方案:直接使用原始音频数据量过大不现实,因此需要量化,随后介绍了μ-律变换量化和向量量化的应用&优缺点,最后给出了作者他们采用的模型与一些配置信息
- 从序列波形到离散空间分布的映射(音素 $\leftrightarrow$ 离散标记)不好建立,VALL-E把关系建立的“回归”问题视作条件语言建模任务,用LLM的思路来处理对应关系。这对于说话人特征的表征训练有启发意义。另外分层映射也有意思,就像一个分层的筛子,第一层留下的是最大块的固体物,后续次之而且分布应该是第一层信息“最多”后续各层快速衰减,所以用自回归模型(AR)去预测第一层的编码,非自回归模型(NAR)预测剩下的7层。“先定大框架,再填小细节”
- 采样率降低了 320 倍依然能保留特征,说明真正承载“含义”和“音色”等特征信息的分布是非常稀疏的,大部分是波形的冗余。但是还是存在质量-压缩倍数之间的权衡
第四部分:VALL-E#
4.1 问题概述:把TTS视作条件语言建模任务#
给定数据集$D= { x_i,y_i}$ ,$y$是声音样本而$x = {x_0,x_1,…,x_L}$是其对应的文本音素序列(corresponding phoneme transcription)。我们使用一个预训练的神经编解码模型,把每个声音样本编码成离散的声学编码,表示为编码$(y)= C^{T\times8}$。$C$表示二维声学编码矩阵,$T$是下采样得到的的声音序列长度。在这个矩阵中,行向量$c_{t,()}$表示第t帧/时间步的8个量化层的编码值;列向量$c_{(),j}$表示由第$j$个量化层对应的码表中的编码组成的序列。在这个量化过程结束后,神经编解码器的解码器能够重建(有损)波形,表示为$Decodec(C)\approx\hat{y}$。
零样本TTS需要模型能够合成高质量的未见过说话人的语音。在这篇工作中,我们把零样本TTS视作一个条件编解码语言建模任务。我们训练一个神经语言模型,基于一段音素序列$x$(对应要合成的文本内容)和一个声学prompt矩阵$\widetilde{C}^{T^{’}\times8}$来合成声学编码矩阵$C$。而我们的优化任务目标就是要最大化概率$p(C|x,\widetilde{C})$,即已知声学prompt矩阵和音素序列合成某种特定的声音编码矩阵$C$的可能性。这里的$\widetilde{C}$是一段注册音频输入相同的神经编解码器而获得的。我们预期神经语言模型能学到如何从音素序列和声学提示中提取到内容信息和说话人信息。从而在推理生成输出时,提供一段音素序列和一段3s时长的未见过说话人的注册音频,训练过的语言模型就能“估计”出具有需要合成内容以及说话人音色的声学编码矩阵。然后神经编解码器的解码器部分就能合成出高质量的说话人语言。
4.2 训练:条件编解码语言建模#
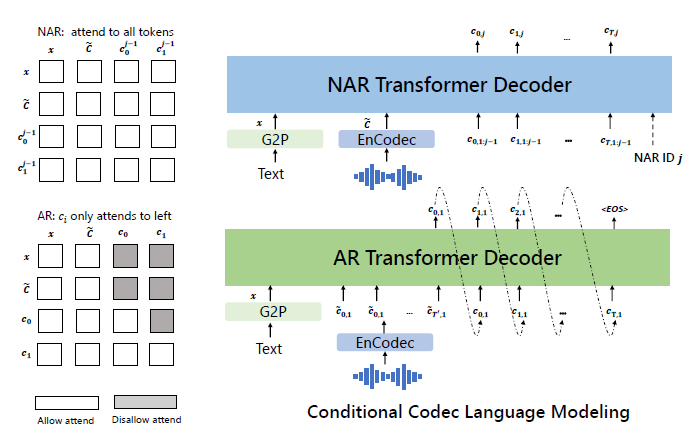
神经编解码模型让我们能够操作离散的声学表示。由于神经编解码模型中的残差量化过程特性,这些声学标记带有层次结构特征:由靠前的量化层产生的标记包含声学特征如说话人信息,后续的量化层包含声学细节信息。每一个量化层都是被训练于用来建模此前的量化层的残差信息。受此启发,我们设计了两种层级化的条件语言模型。
对于第一个量化层的$c_{1,()}$,我们训练一个自回归的语言模型,它基于音素序列$x$和声学提示 $\tilde{C}{:,1}$,其公式如下: $$ p(c{:,1}|x,\tilde{C}{:,1};\theta{AR}) = \prod_{t=0}^{T}p(c_{t,1}|c_{<t,1},\tilde{c}{:,1},x;\theta{AR}) $$ 由于VALL-E是一个decoder-only的语言模型,$\tilde{c}{:,1}$ (声学提示)与 $c{:,1}$(生成内容) 是拼接构成一个完整的序列,我们在训练中并不去区分它们/插入特定的标记。在推理阶段,模型仅预测 $c_{:,1}$,前缀 $\tilde{c}_{:,1}$ 作为已知条件给出。
对于产生自第二到第八个量化层的离散标记 $c_{:, j \in [2,8]}$,我们训练了一个非自回归语言模型。由于在 NAR 模式下标记之间无法相互访问(不具备顺序关系),为了约束说话人身份,我们使用了完整的声学提示矩阵 $\tilde{C}$ 作为声学提示。因此,该模型以音素序列 $x$、声学提示 $\tilde{C}$ 以及属于先前码本的已预测声学标记 $C_{:, <j}$ 为条件,其公式如下 :
$$ p(C_{:,2:8}|x,\tilde{C};\theta_{NAR}) = \prod_{j=2}^{8}p(c_{:,j}|C_{:,<j},x,\tilde{C};\theta_{NAR}) $$ 结合使用AR模型和NAR模型使得我们在语音质量和推理速度之间取得了良好的平衡效果。一方面,出于语音质量的考虑,生成得到的语音的语速应当与参考注册音频一致,另一方面,不同说话人之间的语速差异极大,而且很难直接训练一个通用于不同说话人的长度预测器。在这种情况下,AR模型由于其天生的声学序列长度预测上的灵活性,成为了自然的选择。另一方面,对于这之后的阶段,输出槽位(output slots)数量已经由第一阶段的序列长度固定了,后续会遵循它,因此可以使用NAR模型把时间复杂度从$O(T)$降低至$O(1)$以提高推理速度。总而言之,预测$C$的过程可以被建模为 $$ p(C|x,\tilde{C};\theta)=p(c_{:,1}|\tilde{C}{:,1},X;\theta{AR})\prod_{j=2}^{8}p(c_{:,j}|c_{:,<j},x,\tilde{C};\theta_{NAR}) $$
4.2.1 自回归编解码器语言建模#
自回归语言模型负责生成来自第一个量化层的标记。它由音素嵌入层 $W_x$、声学嵌入层 $W_a$、Transformer 解码器以及一个预测层组成。为了生成具有特定内容的语音,我们将音素序列用作该语言模型的音素prompt。因此,模型的输入是拼接 $x$ 和 $c_{:,1}$ 而来的,且在它们各自的末尾都附加了一个特殊的 <EOS> 标记。我们分别为提示标记和输入标记计算正弦位置嵌入。对于该因果(causal)Transformer 模型,每个标记 $c_{t,1}$ 都可以关注到($x, c_{<t,1}$)(它左侧的),如图三所示。模型的优化目标是最大化第一个码本中下一个标记出现的概率。我们将输出投影层(output projection layer)的参数与声学嵌入层 $W_a$ 的参数共享。
在自回归模型中,我们在训练期间并不显式地提取一段音频剪辑作为提示。其训练过程是纯粹的因果语言模型训练。通过这种方式,任何前缀序列 $c_{<t,1}$ 都被视为序列后半部分 $c_{\ge t,1}$ 的提示。在推理阶段,给定一段注册音频(Enrolled Recording)时,我们应当将注册音频的音素序列与待合成文本的音素序列拼接在一起 。同时,注册音频的声学标记序列将被用作自回归解码的前缀,如4.2中的第一个公式所定义。我们将在实验中研究这一设置的优越性。
4.2.2 非自回归编码器建模#
当我们通过自回归模型获得第一层量化器编码后,我们采用非自回归模型来生成其他七个量化器的编码。除了包含八个独立的声学嵌入层外,非自回归模型的架构与自回归模型相似。在每个训练步骤中,我们随机采样一个训练阶段 $i \in [2, 8]$ 。模型的训练目标是最大化来自第 $i$ 个量化器码本的声学标记预测概率。第 1 阶段到第 $i-1$ 阶段的声学标记会被嵌入并累加,作为模型的输入:
$$ e_{c_{t,j}} = W_{a}^{j} \odot c_{t,j} $$ $$ e_{c_t} = \sum_{j=1}^{i-1} e_{c_{t,j}} $$
其中 $\odot$ 表示索引选择操作。需要注意的是音素序列同样被作为该语言模型的提示。此外,为了克隆特定说话人的独特音色,我们还使用注册语音的声学标记作为声学提示。具体而言,我们首先使用神经编解码器模型将注册语音转化为声学标记矩阵 $\tilde{C}^{T \times 8}$ 。所有八个码本的嵌入表示被累加在一起,作为声学提示 $e_{\tilde{c}t} = \sum{j=1}^{8} e_{\tilde{c}{t,j}}$ 。为了预测第 $i$ 个码本的声学标记,Transformer 的输入是 $(e_x, e{\tilde{c}}, e_{c_{:, <i}})$ 的拼接。我们同样分别为提示和声学序列独立计算位置嵌入。当前阶段 $i$ 通过自适应层归一化注入到网络中,即 $AdaLN(h, i)$ = $a_i LayerNorm(h)$ + $b_i$,其中 $h$ 是中间激活值,$a_i$ 和 $b_i$ 通过对阶段嵌入进行线性投影获得 。
与自回归模型不同,非自回归模型允许每个标记在自注意力层中关注到所有的输入标记。我们还共享了声学嵌入层和输出预测层的参数,这意味着第 $j$ 个预测层的权重与第 $j+1$ 个声学嵌入层的权重相同。
4.3 推理:通过提示实现的上下文学习#
上下文学习能力是基于文本的语言模型所拥有的一种相当惊艳的能力。它使得我们能够在不对参数进行额外更新的情况下预测未见过输入的“标签”。对于TTS而言,如果模型能够在不微调本身的情况下合成高质量的未见过说话人的语音,那这个模型就被认定为是具备了上下文学习能力。然而目前现有的TTS系统的上下文学习能力都很一般,它们不进行额外的微调的话,合成未见说话人的性能就会明显降低。
对于语言模型而言,提示是零样本场景下实现上下文学习能力的必要条件。我们设计的提示与推理过程如下所示:首先将待合成文本转化为音素序列,将注册音频编码为声学提示矩阵,二者分别作为音素提示和声学提示。这两种提示都会被同时用于AR/NAR模型。对于AR模型而言,因为我们观察到束搜索(beam search)可能会导致语言模型陷入无限循环,所以我们使用以提示为条件的基于采样的解码。更进一步的,采样步骤能够显著提高输出的多样性。对于NAR模型,我们使用贪婪解码(greedy decoding)来选择概率最高的标记。最后,我们基于这八层编码序列,使用神经编解码器的解码器部分来生成声音波形。声学提示和待合成语音在语义上可能有关也可能无关(?),这就有了以下两种情况:
- VALL-E :我们的主要目的是为未见过的说话人生成指定的音频内容。给定模型一段文本句子、一段注册音频及这段音频对应的转写文本。我们将注册语音的转写文本得到的转写音素拼接到给定句子的音素序列之前作为声学提示。然后用注册语音的第一层声学标记 $\tilde{c}_{:,1}$作为声学前缀。依靠音素提示和升学前缀,VALL-E能够生成给定文本的声学标记,进而得到了该说话人的声音克隆。
- VALL-E-continual:在这种设置下,我们分别使用完整的转写文本和话语的前3秒作为音素提示和声学提示,并要求模型生成后续部分。推理过程与 VALL-E 设置相同,不同之处在于注册语音与生成的语音在文本语义上是连续的。
第四部分详细描述了VALL-E的模型架构设计思路,读完之后能切实体会到“把语音合成建模为一种条件语言建模任务“”这句话是怎么被体现出来的。模型结构比我想象的要简单,但AR和NAR的结合使用很精妙而且具有说服力。
语言模型陷入无限循环(looping)我在此前进行过的图片描述生成任务中尝试自行构建transformer模型时也遇到过,并且最终也未能解决。““在对第t个token做概率预测时,实际上是根据前面t-1个词做最大后验估计的,对于那些重复生成的文本 (这里以ABCDE -> HJIKLLLLLLLLLL…为例),当第一个L生成后,后面位置上L对应索引的softmax值依然是最大的……模型会倾向于从前面已经预测的word里面挑选最匹配的词……这是模型对于该任务找到的一个“捷径”。”
对于我的基于文本的零样本语音合成任务,如果是应用于类似VALL-E结构的模型的话,其适配器的目标就非常明确了:将 RoBERTa 提取的文本特征映射到与 $\tilde{c}_{:,1}$(第一层声学 Token)等价的语义空间中,从而用“文本提示”取代“声学提示”,并且训练目的不是还原说话人声音特征而是表征文本提示中的特征。用公式对比的话就是
VALL-E 的 $p$:$p(C | x, \text{Acoustic Prompt})$
我的工作的 $p$:$p(C | x, \text{Text Description})$
我提取的文本语义嵌入 ,需要能够提供和3秒音频相比相同甚至更丰富的约束信息,从而"指引"概率函数 $p$ 指向正确的声学空间区域。
值得注意的是,这里的NAR模型需要完整的8层信息作为输入来约束说话人身份,那我要做的适配器也需要有足够的“表现力”才能指导模型生成符合描述的细节特征。
参考 VALL-E 的逻辑,前序量化器负责身份,后续量化器负责细节 。虽然不是明确的表明,但这也部分实现了“特征解耦”的效果。或许我可以尝试在适配器设计中将“音色描述”映射到前几层,而将“环境描述”“情绪描述”等映射到后几层的引导中。
引用#
(state-of-the-art,某领域内表现最好的模型) ↩︎
(Comparision Mean Option Score,CMOS,主观评分。测试人员每次听两个音频,并使用一个测试中的分数来评估后者与前者相比的感觉,+为更好-为更差,范围为[−3,3]) ↩︎
(Similarity Mean Option Score,SMOS,主观评分。听众根据“这两段声音听起来是否像同一个人”进行打分) ↩︎
(Sercan Ömer Arik, Jitong Chen, Kainan Peng, Wei Ping, and Yanqi Zhou. Neural voice cloning with a few samples. In NeurIPS, pages 10040–10050, 2018.) ↩︎
(Yutian Chen, Yannis M. Assael, Brendan Shillingford, David Budden, Scott E. Reed, Heiga Zen,Quan Wang, Luis C. Cobo, Andrew Trask, Ben Laurie, Çaglar Gülçehre, Aäron van den Oord,Oriol Vinyals, and Nando de Freitas. Sample efficient adaptive text-to-speech. In ICLR , 2019) ↩︎
(Tao Wang, Jianhua Tao, Ruibo Fu, Jiangyan Yi, Zhengqi Wen, and Rongxiu Zhong. Spoken content and voice factorization for few-shot speaker adaptation. In Interspeech, pages 796–800. ISCA,2020.) ↩︎
(Mingjian Chen, Xu Tan, Bohan Li, Yanqing Liu, Tao Qin, Sheng Zhao, and Tie-Yan Liu. Adaspeech:Adaptive text to speech for custom voice. In ICLR, 2021.) ↩︎
(Sung-Feng Huang, Chyi-Jiunn Lin, Da-Rong Liu, Yi-Chen Chen, and Hung-yi Lee. Meta-tts: Metalearningfor few-shot speaker adaptive text-to-speech. IEEE ACM Trans. Audio Speech Lang.Process., 30:1558–1571, 2022.) ↩︎
(Weicheng Cai, Jinkun Chen, and Ming Li. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system. In Odyssey 2018: The Speaker and Language Recognition Workshop, 26-29 June 2018, Les Sables d’Olonne, France, pages 74–81. ISCA, 2018.) ↩︎
(Xu Tan, Tao Qin, Frank K. Soong, and Tie-Yan Liu. A survey on neural speech synthesis. CoRR,abs/2106.15561, 2021.) ↩︎
(Yihan Wu, Xu Tan, Bohan Li, Lei He, Sheng Zhao, Ruihua Song, Tao Qin, and Tie-Yan Liu.Adaspeech 4: Adaptive text to speech in zero-shot scenarios. In Interspeech 2022, 23rd Annual Conference of the International Speech Communication Association, Incheon, Korea, 18-22 September 2022, pages 2568–2572. ISCA, 2022. doi: 10.21437/Interspeech.2022-901.) ↩︎
(Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail A. Kudinov. Grad-tts:A diffusion probabilistic model for text-to-speech. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pages 8599–8608.PMLR, 2021. URL http://proceedings.mlr.press/v139/popov21a.html.) ↩︎
(Heeseung Kim, Sungwon Kim, and Sungroh Yoon. Guided-tts: A diffusion model for text-to-speech via classifier guidance. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors, International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 11119–11133. PMLR, 2022.) ↩︎
(Kushal Lakhotia, Evgeny Kharitonov, Wei-Ning Hsu, Yossi Adi, Adam Polyak, Benjamin Bolte,Tu Anh Nguyen, Jade Copet, Alexei Baevski, Adelrahman Mohamed, and Emmanuel Dupoux.Generative spoken language modeling from raw audio. CoRR, abs/2102.01192, 2021.) ↩︎
(Adam Polyak, Yossi Adi, Jade Copet, Eugene Kharitonov, Kushal Lakhotia, Wei-Ning Hsu, Abdelrahman Mohamed, and Emmanuel Dupoux. Speech resynthesis from discrete disentangled self-supervised representations. In Interspeech, pages 3615–3619. ISCA, 2021.) ↩︎
(Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, MatthewSharifi, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. Audiolm: a language modeling approach to audio generation. CoRR, abs/2209.03143, 2022.) ↩︎
(Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. In NeurIPS, 2020.) ↩︎
(Yu-An Chung, Yuxuan Wang, Wei-Ning Hsu, Yu Zhang, and R. J. Skerry-Ryan. Semi-supervised training for improving data efficiency in end-to-end speech synthesis. In ICASSP, pages 6940–6944. IEEE, 2018.) ↩︎
(Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, et al. Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5723–5738, 2022.) ↩︎
(Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning.In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 6306–6315,2017.) ↩︎
(He Bai, Renjie Zheng, Junkun Chen, Mingbo Ma, Xintong Li, and Liang Huang. A^3^t: Alignment-aware acoustic and text pretraining for speech synthesis and editing. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 1399–1411. PMLR, 2022.) ↩︎