知乎收藏夹 Pro:用 AI 辅助整理知乎收藏#
常年刷知乎收藏的内容越来越多,随手丢进默认文件夹之后懒没有整理过……时间一长成屎山了……,查找特定类别变得困难。于是搓了一个脚本尝试解决这个问题,花了两天迭代三十多次,在Gemini的大力支持下达成了一个比较满意的效果……
主要功能#
1. 为收藏夹生成描述#
如果一个收藏夹里存放了大量文章,可能很难记清它的主要内容。这个功能可以帮助快速生成一个概括性的描述。
在收藏夹页面,脚本会添加一个按钮。点击后,它会读取当前页面上文章的标题和部分内容,然后调用 AI 生成一段描述。用户可以修改这段描述,确认后保存。
2. 智能整理收藏夹#
这是脚本的核心功能,用于将文章从一个收藏夹自动分类到其他收藏夹。
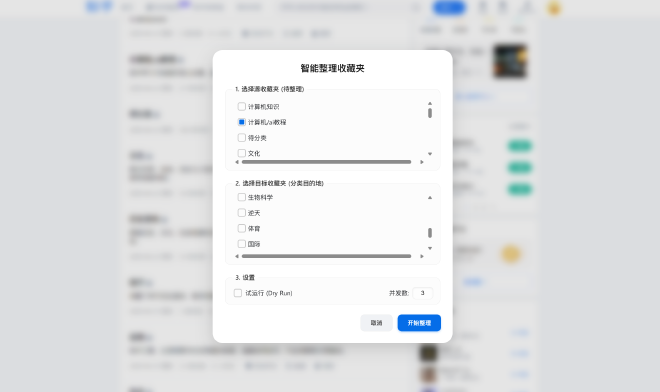
用户首先需要选择一个或多个“源收藏夹”(待整理的)和“目标收藏夹”(分类目的地)。脚本会依次处理源收藏夹中的每篇文章,通过 AI 判断它最适合哪个目标收藏夹,然后执行移动操作。 移动等操作用到了从网页端分析获得的api端口,应该速度还可以。 这个过程包含几个辅助设计:
- 试运行 (Dry Run):这是一个安全选项。勾选后,脚本只会分析并报告每篇文章建议的移动路径,不会真的移动文件。用户可以先查看 AI 的分类结果是否合理。
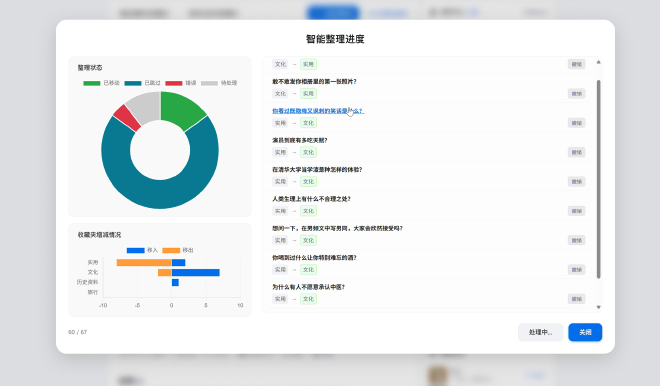
- 进度仪表盘:整理过程是可视的。界面会显示一个仪表盘,包含图表和日志,用于展示整理进度、分类统计和每一项操作的详细记录。
- 可筛选的日志:用户可以通过点击图表来筛选日志,方便查看特定分类的操作历史。
- 撤销功能:所有被移动的文章都可以在日志中单独撤销,将文章移回原处。
技术实现#
1. 为什么用油猴脚本?#
使用 Tampermonkey作为平台主要有以下几个原因:
- 直接操作页面:脚本可以直接在知乎页面上运行,方便地添加按钮、窗口等 UI 元素。
- 利用现有登录状态:脚本执行时,浏览器会自动携带用户的登录 Cookie。这意味着在调用知乎需要登录权限的 API(如添加或删除收藏)时,不需要额外处理复杂的登录和验证流程。
- 绕过 API 签名:知乎的一些内容接口有
x-zse-96签名保护,在前端脚本中逆向很困难。通过使用油猴提供的GM_xmlhttpRequest,可以直接请求页面的 HTML,从而获取内容,绕开了调用这些受保护接口的需要,同时也降低了被封号的风险。
2. “生成描述”的流程#
这个功能的实现分为三步:
- 数据采集:脚本遍历当前页面上的文章元素,提取标题和正文。如果内容被折叠,会模拟点击“展开”按钮。
- 构建 Prompt 并调用 AI:将采集到的文本数据整理后,发送给 AI,要求它生成一段总结性的文字。
- 应用更改:用户确认后,脚本通过知乎的官方 API (
PUT /api/v4/collections/{id}) 来更新收藏夹的描述。
3. “智能整理”的技术细节#
比较复杂的部分,它的工作流程如下:
a. 获取文章列表#
首先需要拿到源收藏夹里的所有文章。通过分析网络请求,可以发现知乎有一个分页 API (/api/v4/collections/{collectionId}/items),通过循环调用这个 API 就可以获取完整的文章列表。
b. 抓取文章正文#
拿到文章链接后,需要获取其正文内容以供 AI 分析。直接调用内容 API 不太可行,有签名限制。这里的解决方法是:
使用
GM_xmlhttpRequest来请求每个文章链接的 HTML 全文。这是一个油猴脚本的特有函数,可以实现跨域的异步网络请求。
获取到 HTML 文本后,使用浏览器内置的 DOMParser API 将其转换为 DOM 对象,然后就可以用 querySelector 轻松提取出正文所在的元素(.RichText.ztext)了。
c. 并发控制#
如果短时间内对大量文章发起请求,可能会被限制。为了避免这个问题,实现了一个简单的并发控制逻辑。
const taskQueue = [...all_articles];
const CONCURRENCY = 3; // 设置同时运行的任务数量
async function worker() {
while (taskQueue.length > 0) {
const task = taskQueue.shift(); // 从队列头部取一个任务
await processTask(task); // 执行任务(抓取、分析、移动)
}
}
// 启动 3 个 "worker" 并行处理任务
for (let i = 0; i < CONCURRENCY; i++) {
worker();
}
这样可以保证脚本以一个稳定的速率执行任务。
d. 可视化界面#
为了让整理过程可视化程度更高,用 Chart.js 这个库来制作图表,展示任务状态和分类结果。图表和日志列表是联动的,点击图表可以筛选日志,方便查看自己关心的信息。
不过Chart.js好像有缩放bug,ctrl+shift+移动滚轮有惊喜
后续计划#
目前脚本功能已经可用,但还有一些可以改进的地方:
-[] 界面优化:适配知乎的夜间模式
-[] 增加模型选项:允许用户选择不同的 AI 模型,同时优化prompt生成,目前的版本还是有点费tokens
-[] 功能扩展:一个长远的想法是尝试替换知乎原生的收藏按钮,简化收藏流程,在收藏时就介入AI分类建议
-[] 修复bug:已知的包括一篇文章处于多个收藏夹时会重复POST、左下类别太多时坐标y轴会显示不完整……
-[] 拓展平台:csdn等文字平台也有类似的问题,不过还没成屎山就先放放……视频平台收藏分类管理得还不错,就算了先~
FINAL#
这个脚本是一个临时起意的idea,目的是解决自己在使用知乎时遇到的一个具体问题,自我感觉还挺实用的……
Reply by Email